keepalived原理(主从配置+haproxy)及配置文件详解
- 来源:开源中国
- 更新日期:2018-03-28
摘要: 下图描述了使用keepalived+Haproxy主从配置来达到能够针对前段流量进行负载均衡到多台后端web1、web2、web3、img1、img2.但是由于haproxy会存在单点故障问题,因此使用keepalived来实现对Haproxy单点问题的高可用处理。 下图描述了使用keepalived+Haproxy主从配置来达到能够针对前段流量进行负载均衡到多台后端web1、web2、web3、img1、img2.但是由于h
使用keepalived+Haproxy主从配置来达到能够针对前段流量进行负载均衡到多台后端web1、web2、web3、img1、img2.但是由于haproxy会存在单点故障问题,因此使用keepalived来实现对Haproxy单点问题的高可用处理。
1>keepalived原理及配置介绍
什么是Keepalived呢,keepalived观其名可知,保持存活,在网络里面就是 保持在线 了,也就是所谓的高可用或热备,用来防止单点故障(单点故障是指一旦某一点出现故障就会导致整个系统架构的不可用)的发生, Keepalived通过请求一个vip来达到请求真是IP地址的功能,而VIP能够在一台机器发生故障时候,自动漂移到另外一台机器上,从来达到了高可用HA功能。 那说到keepalived时不得不说的一个协议就是VRRP协议,可以说这个协议就是keepalived实现的基础,那么首先我们来看看VRRP协议。
注:搞运维的要有足够的耐心,不理解协议就很难透彻的掌握keepalived的了
学过网络的朋友都知道,网络在设计的时候必须考虑到冗余容灾,包括线路冗余,设备冗余等,防止网络存在单点故障,那在路由器或三层交换机处实现冗余就显得尤为重要,在网络里面有个协议就是来做这事的,这个协议就是VRRP协议,Keepalived就是巧用VRRP协议来实现高可用性(HA)的
VRRP协议有一篇文章写的非常好,大家可以直接看这里(记得认真看看哦,后面基本都已这个为基础的了)
帖子地址: http://bbs.ywlm.net/thread-790-1-1.html
只需要把服务器当作路由器即可!
在《 VRRP协议 》里讲到了虚拟路由器的ID也就是VRID在这里比较重要
keepalived完全遵守VRRP协议,包括竞选机制等等
Keepalived原理
keepalived也是模块化设计,不同模块复杂不同的功能,下面是keepalived的组件
core check vrrp libipfwc libipvs-2.4 libipvs-2.6
core:是keepalived的核心,复杂主进程的启动和维护,全局配置文件的加载解析等
check:负责healthchecker(健康检查),包括了各种健康检查方式,以及对应的配置的解析包括LVS的配置解析
vrrp:VRRPD子进程,VRRPD子进程就是来实现VRRP协议的
libipfwc:iptables(ipchains)库,配置LVS会用到
libipvs*:配置LVS会用到
注意,keepalived和LVS完全是两码事,只不过他们各负其责相互配合而已
keepalived启动后会有三个进程
父进程:内存管理,子进程管理等等
子进程:VRRP子进程
子进程:healthchecker子进程
有图可知,两个子进程都被系统WatchDog看管,两个子进程各自复杂自己的事,healthchecker子进程复杂检查各自服务器的健康程度,例如HTTP,LVS等等,如果healthchecker子进程检查到MASTER上服务不可用了,就会通知本机上的兄弟VRRP子进程,让他删除通告,并且去掉虚拟IP,转换为BACKUP状态
keepalived配置详解
keepalived有三类配置区域(姑且就叫区域吧),注意不是三种配置文件,是一个配置文件里面三种不同类别的配置区域
全局配置(Global Configuration)
VRRPD配置
LVS配置
一,全局配置
全局配置又包括两个子配置:
全局定义(global definition)
静态路由配置(static ipaddress/routes)
1,全局定义(global definition) 配置范例
全局配置解析
global_defs全局配置标识,表面这个区域{}是全局配置
表示keepalived在发生诸如切换操作时需要发送email通知,以及email发送给哪些邮件地址,邮件地址可以多个,每行一个
notification_email_from admin@example.com
表示发送通知邮件时邮件源地址是谁
smtp_server 127.0.0.1
表示发送email时使用的smtp服务器地址,这里可以用本地的sendmail来实现
smtp_connect_timeout 30
连接smtp连接超时时间
router_id node1
机器标识
2,静态地址和路由配置范例
这里实际上和系统里面命令配置IP地址和路由一样例如:
192.168.1.1/24 brd + dev eth0 scope global 相当于: ip addr add 192.168.1.1/24 brd + dev eth0 scope global
就是给eth0配置IP地址
路由同理
一般这个区域不需要配置
这里实际上就是给服务器配置真实的IP地址和路由的,在复杂的环境下可能需要配置, 一般不会用这个来配置 ,我们可以直接用vi /etc/sysconfig/network-script/ifcfg-eth1来配置,切记这里可不是VIP哦,不要搞混淆了,切记切记!
二,VRRPD配置
VRRPD配置包括三个类
VRRP同步组(synchroization group)
VRRP实例(VRRP Instance) VRRP脚本
1,VRRP同步组(synchroization group)配置范例
其中:
http和mysql是实例名和下面的实例名一致
notify /path/to/notify.sh:
smtp alter表示切换时给global defs中定义的邮件地址发送右键通知
2,VRRP实例(instance) 配置范例
state: state指定instance(Initial)的初始状态,就是说在配置好后,这台服务器的初始状态就是这里指定的,但这里指定的不算,还是得要通过竞选通过优先级来确定,里如果这里设置为master,但如若他的优先级不及另外一台,那么这台在发送通告时,会发送自己的优先级,另外一台发现优先级不如自己的高,那么他会就回抢占为master
interface: 实例绑定的网卡,因为在配置虚拟IP的时候必须是在已有的网卡上添加的
dont track primary: 忽略VRRP的interface错误
track interface: 跟踪接口,设置额外的监控,里面任意一块网卡出现问题,都会进入故障(FAULT)状态,例如,用nginx做均衡器的时候,内网必须正常工作,如果内网出问题了,这个均衡器也就无法运作了,所以必须对内外网同时做健康检查
mcast src ip: 发送多播数据包时的源IP地址,这里注意了,这里实际上就是在那个地址上发送VRRP通告,这个非常重要,一定要选择稳定的网卡端口来发送,这里相当于heartbeat的心跳端口,如果没有设置那么就用默认的绑定的网卡的IP,也就是interface指定的IP地址
garp master delay: 在切换到master状态后,延迟进行免费的ARP(gratuitous ARP)请求
virtual router id: 这里设置VRID,这里非常重要,相同的VRID为一个组,他将决定多播的MAC地址
priority 100: 设置本节点的优先级,优先级高的为master
advert int: 检查间隔,默认为1秒
virtual ipaddress: 这里设置的就是VIP,也就是虚拟IP地址,他随着state的变化而增加删除,当state为master的时候就添加,当state为backup的时候删除,这里主要是有优先级来决定的,和state设置的值没有多大关系,这里可以设置多个IP地址
virtual routes: 原理和virtual ipaddress一样,只不过这里是增加和删除路由
lvs sync daemon interface: lvs syncd绑定的网卡
authentication: 这里设置认证
auth type: 认证方式,可以是PASS或AH两种认证方式
auth pass: 认证密码
nopreempt: 设置不抢占,这里只能设置在state为backup的节点上,而且这个节点的优先级必须别另外的高
preempt delay: 抢占延迟
debug: debug级别
notify master: 和sync group这里设置的含义一样,可以单独设置,例如不同的实例通知不同的管理人员,http实例发给网站管理员,mysql的就发邮件给DBA
3,VRRP脚本
首先在vrrp_script区域定义脚本名字和脚本执行的间隔和脚本执行的优先级变更
vrrp_script check_running { script "/usr/local/bin/check_running" interval 10 #脚本执行间隔 weight 10 #脚本结果导致的优先级变更:10表示优先级+10;-10则表示优先级-10 } 然后在 实例 ( vrrp_instance )里面引用,有点类似脚本里面的函数引用一样:先定义,后引用函数名
track_script {
check_runningweight 20
}
注意:VRRP脚本(vrrp_script)和VRRP实例( vrrp_instance )属于同一个级别
如果你没有配置LVS+keepalived那么无需配置这段区域,里如果你用的是nginx来代替LVS,这无限配置这款,这里的LVS配置是专门为keepalived+LVS集成准备的。
注意了,这里LVS配置并不是指真的安装LVS然后用ipvsadm来配置他,而是用keepalived的配置文件来代替ipvsadm来配置LVS,这样会方便很多,一个配置文件搞定这些,维护方便,配置方便是也!
这里LVS配置也有两个配置
一个是虚拟主机组配置
一个是虚拟主机配置
1,虚拟主机组配置文件详解
这个配置是可选的,根据需求来配置吧,这里配置主要是为了让一台realserver上的某个服务可以属于多个Virtual Server,并且只做一次健康检查
virtual_server_group <STRING> {
# VIP port
<IPADDR> <PORT>
<IPADDR> <PORT>
fwmark <INT>
}
2,虚拟主机配置
virtual server可以以下面三种的任意一种来配置
下面以第一种比较常用的方式来配详细解说一下
virtual_server 192.168.1.2 80 { #设置一个virtual server: VIP:Vport
delay_loop 3 # service polling的delay时间,即服务轮询的时间间隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh #LVS调度算法
lb_kind NAT|DR|TUN #LVS集群模式
persistence_timeout 120 #会话保持时间(秒为单位),即以用户在120秒内被分配到同一个后端realserver
persistence_granularity <NETMASK> #LVS会话保持粒度,ipvsadm中的-M参数,默认是0xffffffff,即每个客户端都做会话保持
protocol TCP #健康检查用的是TCP还是UDP
ha_suspend #suspendhealthchecker’s activity
virtualhost <string> #HTTP_GET做健康检查时,检查的web服务器的虚拟主机(即host:头)
sorry_server <IPADDR> <PORT> #备用机,就是当所有后端realserver节点都不可用时,就用这里设置的,也就是临时把所有的请求都发送到这里啦
real_server <IPADDR> <PORT> #后端真实节点主机的权重等设置,主要,后端有几台这里就要设置几个
{
weight 1 #给每台的权重,0表示失效(不知给他转发请求知道他恢复正常),默认是1
inhibit_on_failure #表示在节点失败后,把他权重设置成0,而不是冲IPVS中删除
notify_up <STRING> | <QUOTED-STRING>#检查服务器正常(UP)后,要执行的脚本
notify_down <STRING> | <QUOTED-STRING> #检查服务器失败(down)后,要执行的脚本
HTTP_GET #健康检查方式
{
url { #要坚持的URL,可以有多个
path / #具体路径
digest <STRING>
status_code 200 #返回状态码
}
connect_port 80 #监控检查的端口
bindto <IPADD> #健康检查的IP地址
connect_timeout 3 #连接超时时间
nb_get_retry 3 #重连次数
delay_before_retry 2 #重连间隔
} # END OF HTTP_GET|SSL_GET
#下面是常用的健康检查方式,健康检查方式一共有HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK这些
#TCP方式
TCP_CHECK {
connect_port 80
bindto 192.168.1.1
connect_timeout 4
} # TCP_CHECK
# SMTP方式 ,这个可以用来给邮件服务器做集群
SMTP_CHECK
host {
connect_ip <IP ADDRESS>
connect_port <PORT> #默认检查25端口
14 KEEPALIVED
bindto <IP ADDRESS>
}
connect_timeout <INTEGER>
retry <INTEGER>
delay_before_retry <INTEGER>
# "smtp HELO"?|·- ?ê§?à "
helo_name <STRING>|<QUOTED-STRING>
} #SMTP_CHECK
#MISC方式 ,这个可以用来检查很多服务器只需要自己会些脚本即可
MISC_CHECK
{
misc_path <STRING>|<QUOTED-STRING> #外部程序或脚本
misc_timeout <INT> #脚本或程序执行超时时间
misc_dynamic #这个就很好用了,可以非常精确的来调整权重,是后端每天服务器的压力都能均衡调配,这个主要是通过执行的程序或脚本返回的状态代码来动态调整weight值,使权重根据真实的后端压力来适当调整,不过这需要有过硬的脚本功夫才行哦
#返回0:健康检查没问题,不修改权重
#返回1:健康检查失败,权重设置为0
#返回2-255:健康检查没问题,但是权重却要根据返回代码修改为 返回码-2 ,例如如果程序或脚本执行后返回的代码为200,#那么权重这回被修改为 200-2
}
} # Realserver
} # Virtual Server
配置文件到此就讲完了,下面是一份未加备注的完整配置文件
注意,这里仅仅是罗列,并不是可用的配置文件。里面需要根据自己的时间情况稍加配置才能用。
注:搞运维的要有足够的耐心,不理解协议就很难透彻的掌握keepalived的了
一,VRRP协议
VRRP协议学过网络的朋友都知道,网络在设计的时候必须考虑到冗余容灾,包括线路冗余,设备冗余等,防止网络存在单点故障,那在路由器或三层交换机处实现冗余就显得尤为重要,在网络里面有个协议就是来做这事的,这个协议就是VRRP协议,Keepalived就是巧用VRRP协议来实现高可用性(HA)的
VRRP协议有一篇文章写的非常好,大家可以直接看这里(记得认真看看哦,后面基本都已这个为基础的了)
帖子地址: http://bbs.ywlm.net/thread-790-1-1.html
只需要把服务器当作路由器即可!
在《 VRRP协议 》里讲到了虚拟路由器的ID也就是VRID在这里比较重要
keepalived完全遵守VRRP协议,包括竞选机制等等
二,Keepalived原理
Keepalived原理
keepalived也是模块化设计,不同模块复杂不同的功能,下面是keepalived的组件
core check vrrp libipfwc libipvs-2.4 libipvs-2.6
core:是keepalived的核心,复杂主进程的启动和维护,全局配置文件的加载解析等
check:负责healthchecker(健康检查),包括了各种健康检查方式,以及对应的配置的解析包括LVS的配置解析
vrrp:VRRPD子进程,VRRPD子进程就是来实现VRRP协议的
libipfwc:iptables(ipchains)库,配置LVS会用到
libipvs*:配置LVS会用到
注意,keepalived和LVS完全是两码事,只不过他们各负其责相互配合而已

keepalived启动后会有三个进程
父进程:内存管理,子进程管理等等
子进程:VRRP子进程
子进程:healthchecker子进程
有图可知,两个子进程都被系统WatchDog看管,两个子进程各自复杂自己的事,healthchecker子进程复杂检查各自服务器的健康程度,例如HTTP,LVS等等,如果healthchecker子进程检查到MASTER上服务不可用了,就会通知本机上的兄弟VRRP子进程,让他删除通告,并且去掉虚拟IP,转换为BACKUP状态
三,Keepalived配置文件详解
keepalived配置详解
keepalived有三类配置区域(姑且就叫区域吧),注意不是三种配置文件,是一个配置文件里面三种不同类别的配置区域
全局配置(Global Configuration)
VRRPD配置
LVS配置
一,全局配置
全局配置又包括两个子配置:
全局定义(global definition)
静态路由配置(static ipaddress/routes)
1,全局定义(global definition) 配置范例
global_defs
{
notification_email
{
admin@example.com
}
notification_email_from admin@example.com
smtp_server 127.0.0.1
stmp_connect_timeout 30
router_id node1
}
复制代码{
notification_email
{
admin@example.com
}
notification_email_from admin@example.com
smtp_server 127.0.0.1
stmp_connect_timeout 30
router_id node1
}
global_defs全局配置标识,表面这个区域{}是全局配置
notification_email
{
admin@example.com
admin@ywlm.net
}
复制代码{
admin@example.com
admin@ywlm.net
}
notification_email_from admin@example.com
表示发送通知邮件时邮件源地址是谁
smtp_server 127.0.0.1
表示发送email时使用的smtp服务器地址,这里可以用本地的sendmail来实现
smtp_connect_timeout 30
连接smtp连接超时时间
router_id node1
机器标识
2,静态地址和路由配置范例
static_ipaddress
{
192.168.1.1/24 brd + dev eth0 scope global
192.168.1.2/24 brd + dev eth1 scope global
}
static_routes
{
src $SRC_IP to $DST_IP dev $SRC_DEVICE
src $SRC_IP to $DST_IP via $GW dev $SRC_DEVICE
}
复制代码{
192.168.1.1/24 brd + dev eth0 scope global
192.168.1.2/24 brd + dev eth1 scope global
}
static_routes
{
src $SRC_IP to $DST_IP dev $SRC_DEVICE
src $SRC_IP to $DST_IP via $GW dev $SRC_DEVICE
}
这里实际上和系统里面命令配置IP地址和路由一样例如:
192.168.1.1/24 brd + dev eth0 scope global 相当于: ip addr add 192.168.1.1/24 brd + dev eth0 scope global
就是给eth0配置IP地址
路由同理
一般这个区域不需要配置
这里实际上就是给服务器配置真实的IP地址和路由的,在复杂的环境下可能需要配置, 一般不会用这个来配置 ,我们可以直接用vi /etc/sysconfig/network-script/ifcfg-eth1来配置,切记这里可不是VIP哦,不要搞混淆了,切记切记!
二,VRRPD配置
VRRPD配置包括三个类
VRRP同步组(synchroization group)
VRRP实例(VRRP Instance) VRRP脚本
1,VRRP同步组(synchroization group)配置范例
vrrp_sync_group VG_1 {
group {
http
mysql
}
notify_master /path/to/to_master.sh
notify_backup /path_to/to_backup.sh
notify_fault "/path/fault.sh VG_1"
notify /path/to/notify.sh
smtp_alert
}
复制代码group {
http
mysql
}
notify_master /path/to/to_master.sh
notify_backup /path_to/to_backup.sh
notify_fault "/path/fault.sh VG_1"
notify /path/to/notify.sh
smtp_alert
}
group {
http
mysql
}
复制代码http
mysql
}
notify_master /path/to/to_master.sh:表示当切换到master状态时,要执行的脚本
notify_backup /path_to/to_backup.sh:表示当切换到backup状态时,要执行的脚本
notify_fault "/path/fault.sh VG_1"
复制代码notify_backup /path_to/to_backup.sh:表示当切换到backup状态时,要执行的脚本
notify_fault "/path/fault.sh VG_1"
smtp alter表示切换时给global defs中定义的邮件地址发送右键通知
2,VRRP实例(instance) 配置范例
vrrp_instance http {
state MASTER
interface eth0
dont_track_primary
track_interface {
eth0
eth1
}
mcast_src_ip <IPADDR>
garp_master_delay 10
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
autp_pass 1234
}
virtual_ipaddress {
#<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPT> label <LABEL>
192.168.200.17/24 dev eth1
192.168.200.18/24 dev eth2 label eth2:1
}
virtual_routes {
# src <IPADDR> [to] <IPADDR>/<MASK> via|gw <IPADDR> dev <STRING> scope <SCOPE> tab
src 192.168.100.1 to 192.168.109.0/24 via 192.168.200.254 dev eth1
192.168.110.0/24 via 192.168.200.254 dev eth1
192.168.111.0/24 dev eth2
192.168.112.0/24 via 192.168.100.254
}
nopreempt
preemtp_delay 300
debug
}
复制代码state MASTER
interface eth0
dont_track_primary
track_interface {
eth0
eth1
}
mcast_src_ip <IPADDR>
garp_master_delay 10
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
autp_pass 1234
}
virtual_ipaddress {
#<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPT> label <LABEL>
192.168.200.17/24 dev eth1
192.168.200.18/24 dev eth2 label eth2:1
}
virtual_routes {
# src <IPADDR> [to] <IPADDR>/<MASK> via|gw <IPADDR> dev <STRING> scope <SCOPE> tab
src 192.168.100.1 to 192.168.109.0/24 via 192.168.200.254 dev eth1
192.168.110.0/24 via 192.168.200.254 dev eth1
192.168.111.0/24 dev eth2
192.168.112.0/24 via 192.168.100.254
}
nopreempt
preemtp_delay 300
debug
}
state: state指定instance(Initial)的初始状态,就是说在配置好后,这台服务器的初始状态就是这里指定的,但这里指定的不算,还是得要通过竞选通过优先级来确定,里如果这里设置为master,但如若他的优先级不及另外一台,那么这台在发送通告时,会发送自己的优先级,另外一台发现优先级不如自己的高,那么他会就回抢占为master
interface: 实例绑定的网卡,因为在配置虚拟IP的时候必须是在已有的网卡上添加的
dont track primary: 忽略VRRP的interface错误
track interface: 跟踪接口,设置额外的监控,里面任意一块网卡出现问题,都会进入故障(FAULT)状态,例如,用nginx做均衡器的时候,内网必须正常工作,如果内网出问题了,这个均衡器也就无法运作了,所以必须对内外网同时做健康检查
mcast src ip: 发送多播数据包时的源IP地址,这里注意了,这里实际上就是在那个地址上发送VRRP通告,这个非常重要,一定要选择稳定的网卡端口来发送,这里相当于heartbeat的心跳端口,如果没有设置那么就用默认的绑定的网卡的IP,也就是interface指定的IP地址
garp master delay: 在切换到master状态后,延迟进行免费的ARP(gratuitous ARP)请求
virtual router id: 这里设置VRID,这里非常重要,相同的VRID为一个组,他将决定多播的MAC地址
priority 100: 设置本节点的优先级,优先级高的为master
advert int: 检查间隔,默认为1秒
virtual ipaddress: 这里设置的就是VIP,也就是虚拟IP地址,他随着state的变化而增加删除,当state为master的时候就添加,当state为backup的时候删除,这里主要是有优先级来决定的,和state设置的值没有多大关系,这里可以设置多个IP地址
virtual routes: 原理和virtual ipaddress一样,只不过这里是增加和删除路由
lvs sync daemon interface: lvs syncd绑定的网卡
authentication: 这里设置认证
auth type: 认证方式,可以是PASS或AH两种认证方式
auth pass: 认证密码
nopreempt: 设置不抢占,这里只能设置在state为backup的节点上,而且这个节点的优先级必须别另外的高
preempt delay: 抢占延迟
debug: debug级别
notify master: 和sync group这里设置的含义一样,可以单独设置,例如不同的实例通知不同的管理人员,http实例发给网站管理员,mysql的就发邮件给DBA
3,VRRP脚本
vrrp_script check_running {
script "/usr/local/bin/check_running"
interval 10
weight 10
}
vrrp_instance http {
state BACKUP
smtp_alert
interface eth0
virtual_router_id 101
priority 90
advert_int 3
authentication {
auth_type PASS
auth_pass whatever
}
virtual_ipaddress {
1.1.1.1
}
track_script {
check_running weight 20
}
}
复制代码script "/usr/local/bin/check_running"
interval 10
weight 10
}
vrrp_instance http {
state BACKUP
smtp_alert
interface eth0
virtual_router_id 101
priority 90
advert_int 3
authentication {
auth_type PASS
auth_pass whatever
}
virtual_ipaddress {
1.1.1.1
}
track_script {
check_running weight 20
}
}
首先在vrrp_script区域定义脚本名字和脚本执行的间隔和脚本执行的优先级变更
vrrp_script check_running { script "/usr/local/bin/check_running" interval 10 #脚本执行间隔 weight 10 #脚本结果导致的优先级变更:10表示优先级+10;-10则表示优先级-10 } 然后在 实例 ( vrrp_instance )里面引用,有点类似脚本里面的函数引用一样:先定义,后引用函数名
track_script {
check_runningweight 20
}
注意:VRRP脚本(vrrp_script)和VRRP实例( vrrp_instance )属于同一个级别
LVS配置
如果你没有配置LVS+keepalived那么无需配置这段区域,里如果你用的是nginx来代替LVS,这无限配置这款,这里的LVS配置是专门为keepalived+LVS集成准备的。
注意了,这里LVS配置并不是指真的安装LVS然后用ipvsadm来配置他,而是用keepalived的配置文件来代替ipvsadm来配置LVS,这样会方便很多,一个配置文件搞定这些,维护方便,配置方便是也!
这里LVS配置也有两个配置
一个是虚拟主机组配置
一个是虚拟主机配置
1,虚拟主机组配置文件详解
这个配置是可选的,根据需求来配置吧,这里配置主要是为了让一台realserver上的某个服务可以属于多个Virtual Server,并且只做一次健康检查
virtual_server_group <STRING> {
# VIP port
<IPADDR> <PORT>
<IPADDR> <PORT>
fwmark <INT>
}
2,虚拟主机配置
virtual server可以以下面三种的任意一种来配置
1. virtual server IP port
2. virtual server fwmark int
3. virtual server group string
复制代码2. virtual server fwmark int
3. virtual server group string
virtual_server 192.168.1.2 80 { #设置一个virtual server: VIP:Vport
delay_loop 3 # service polling的delay时间,即服务轮询的时间间隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh #LVS调度算法
lb_kind NAT|DR|TUN #LVS集群模式
persistence_timeout 120 #会话保持时间(秒为单位),即以用户在120秒内被分配到同一个后端realserver
persistence_granularity <NETMASK> #LVS会话保持粒度,ipvsadm中的-M参数,默认是0xffffffff,即每个客户端都做会话保持
protocol TCP #健康检查用的是TCP还是UDP
ha_suspend #suspendhealthchecker’s activity
virtualhost <string> #HTTP_GET做健康检查时,检查的web服务器的虚拟主机(即host:头)
sorry_server <IPADDR> <PORT> #备用机,就是当所有后端realserver节点都不可用时,就用这里设置的,也就是临时把所有的请求都发送到这里啦
real_server <IPADDR> <PORT> #后端真实节点主机的权重等设置,主要,后端有几台这里就要设置几个
{
weight 1 #给每台的权重,0表示失效(不知给他转发请求知道他恢复正常),默认是1
inhibit_on_failure #表示在节点失败后,把他权重设置成0,而不是冲IPVS中删除
notify_up <STRING> | <QUOTED-STRING>#检查服务器正常(UP)后,要执行的脚本
notify_down <STRING> | <QUOTED-STRING> #检查服务器失败(down)后,要执行的脚本
HTTP_GET #健康检查方式
{
url { #要坚持的URL,可以有多个
path / #具体路径
digest <STRING>
status_code 200 #返回状态码
}
connect_port 80 #监控检查的端口
bindto <IPADD> #健康检查的IP地址
connect_timeout 3 #连接超时时间
nb_get_retry 3 #重连次数
delay_before_retry 2 #重连间隔
} # END OF HTTP_GET|SSL_GET
#下面是常用的健康检查方式,健康检查方式一共有HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK这些
#TCP方式
TCP_CHECK {
connect_port 80
bindto 192.168.1.1
connect_timeout 4
} # TCP_CHECK
# SMTP方式 ,这个可以用来给邮件服务器做集群
SMTP_CHECK
host {
connect_ip <IP ADDRESS>
connect_port <PORT> #默认检查25端口
14 KEEPALIVED
bindto <IP ADDRESS>
}
connect_timeout <INTEGER>
retry <INTEGER>
delay_before_retry <INTEGER>
# "smtp HELO"?|·- ?ê§?à "
helo_name <STRING>|<QUOTED-STRING>
} #SMTP_CHECK
#MISC方式 ,这个可以用来检查很多服务器只需要自己会些脚本即可
MISC_CHECK
{
misc_path <STRING>|<QUOTED-STRING> #外部程序或脚本
misc_timeout <INT> #脚本或程序执行超时时间
misc_dynamic #这个就很好用了,可以非常精确的来调整权重,是后端每天服务器的压力都能均衡调配,这个主要是通过执行的程序或脚本返回的状态代码来动态调整weight值,使权重根据真实的后端压力来适当调整,不过这需要有过硬的脚本功夫才行哦
#返回0:健康检查没问题,不修改权重
#返回1:健康检查失败,权重设置为0
#返回2-255:健康检查没问题,但是权重却要根据返回代码修改为 返回码-2 ,例如如果程序或脚本执行后返回的代码为200,#那么权重这回被修改为 200-2
}
} # Realserver
} # Virtual Server
配置文件到此就讲完了,下面是一份未加备注的完整配置文件
global_defs
{
notification_email
{
admin@example.com
}
notification_email_from admin@example.com
smtp_server 127.0.0.1
stmp_connect_timeout 30
router_id node1
}
notification_email
{
admin@example.com
admin@ywlm.net
}
static_ipaddress
{
192.168.1.1/24 brd + dev eth0 scope global
192.168.1.2/24 brd + dev eth1 scope global
}
static_routes
{
src $SRC_IP to $DST_IP dev $SRC_DEVICE
src $SRC_IP to $DST_IP via $GW dev $SRC_DEVICE
}
vrrp_sync_group VG_1 {
group {
http
mysql
}
notify_master /path/to/to_master.sh
notify_backup /path_to/to_backup.sh
notify_fault "/path/fault.sh VG_1"
notify /path/to/notify.sh
smtp_alert
}
group {
http
mysql
}
vrrp_script check_running {
script "/usr/local/bin/check_running"
interval 10
weight 10
}
vrrp_instance http {
state MASTER
interface eth0
dont_track_primary
track_interface {
eth0
eth1
}
mcast_src_ip <IPADDR>
garp_master_delay 10
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
autp_pass 1234
}
virtual_ipaddress {
#<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPT> label <LABEL>
192.168.200.17/24 dev eth1
192.168.200.18/24 dev eth2 label eth2:1
}
virtual_routes {
# src <IPADDR> [to] <IPADDR>/<MASK> via|gw <IPADDR> dev <STRING> scope <SCOPE> tab
src 192.168.100.1 to 192.168.109.0/24 via 192.168.200.254 dev eth1
192.168.110.0/24 via 192.168.200.254 dev eth1
192.168.111.0/24 dev eth2
192.168.112.0/24 via 192.168.100.254
}
track_script {
check_running weight 20
}
nopreempt
preemtp_delay 300
debug
}
virtual_server_group <STRING> {
# VIP port
<IPADDR> <PORT>
<IPADDR> <PORT>
fwmark <INT>
}
virtual_server 192.168.1.2 80 {
delay_loop 3
lb_algo rr|wrr|lc|wlc|lblc|sh|dh
lb_kind NAT|DR|TUN
persistence_timeout 120
persistence_granularity <NETMASK>
protocol TCP
ha_suspend
virtualhost <string>
sorry_server <IPADDR> <PORT>
real_server <IPADDR> <PORT>
{
weight 1
inhibit_on_failure
notify_up <STRING> | <QUOTED-STRING>
notify_down <STRING> | <QUOTED-STRING>
#HTTP_GET方式
HTTP_GET | SSL_GET
{
url {
path /
digest <STRING>
status_code 200
}
connect_port 80
bindto <IPADD>
connect_timeout 3
nb_get_retry 3
delay_before_retry 2
}
}
}
复制代码{
notification_email
{
admin@example.com
}
notification_email_from admin@example.com
smtp_server 127.0.0.1
stmp_connect_timeout 30
router_id node1
}
notification_email
{
admin@example.com
admin@ywlm.net
}
static_ipaddress
{
192.168.1.1/24 brd + dev eth0 scope global
192.168.1.2/24 brd + dev eth1 scope global
}
static_routes
{
src $SRC_IP to $DST_IP dev $SRC_DEVICE
src $SRC_IP to $DST_IP via $GW dev $SRC_DEVICE
}
vrrp_sync_group VG_1 {
group {
http
mysql
}
notify_master /path/to/to_master.sh
notify_backup /path_to/to_backup.sh
notify_fault "/path/fault.sh VG_1"
notify /path/to/notify.sh
smtp_alert
}
group {
http
mysql
}
vrrp_script check_running {
script "/usr/local/bin/check_running"
interval 10
weight 10
}
vrrp_instance http {
state MASTER
interface eth0
dont_track_primary
track_interface {
eth0
eth1
}
mcast_src_ip <IPADDR>
garp_master_delay 10
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
autp_pass 1234
}
virtual_ipaddress {
#<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPT> label <LABEL>
192.168.200.17/24 dev eth1
192.168.200.18/24 dev eth2 label eth2:1
}
virtual_routes {
# src <IPADDR> [to] <IPADDR>/<MASK> via|gw <IPADDR> dev <STRING> scope <SCOPE> tab
src 192.168.100.1 to 192.168.109.0/24 via 192.168.200.254 dev eth1
192.168.110.0/24 via 192.168.200.254 dev eth1
192.168.111.0/24 dev eth2
192.168.112.0/24 via 192.168.100.254
}
track_script {
check_running weight 20
}
nopreempt
preemtp_delay 300
debug
}
virtual_server_group <STRING> {
# VIP port
<IPADDR> <PORT>
<IPADDR> <PORT>
fwmark <INT>
}
virtual_server 192.168.1.2 80 {
delay_loop 3
lb_algo rr|wrr|lc|wlc|lblc|sh|dh
lb_kind NAT|DR|TUN
persistence_timeout 120
persistence_granularity <NETMASK>
protocol TCP
ha_suspend
virtualhost <string>
sorry_server <IPADDR> <PORT>
real_server <IPADDR> <PORT>
{
weight 1
inhibit_on_failure
notify_up <STRING> | <QUOTED-STRING>
notify_down <STRING> | <QUOTED-STRING>
#HTTP_GET方式
HTTP_GET | SSL_GET
{
url {
path /
digest <STRING>
status_code 200
}
connect_port 80
bindto <IPADD>
connect_timeout 3
nb_get_retry 3
delay_before_retry 2
}
}
}
2>keepalived主从配置介绍
环境配置:
172.31.2.31(安装keepalived)(实例配置里面的VIP为172.31.2.100)
172.31.2.32(安装keepalived)(实例配置里面的VIP为172.31.2.100)
注:
本次实验中,必须能让上述两台机器的keepalived能够通信(增加相应iptables规则或者临时实验关闭iptables -F)
两台机器需要时间同步:简单起见都执行: ntpdatecn.pool.ntp.org
keepalived的日志默认在: tailf/var/log/messages
上述两台机器都需要安装keepalived:
yum install keepalived -y
配置主节点:172.31.2.31
vim /etc/keepalived/keepalived.conf

配置从节点:172.31.2.32
vim /etc/keepalived/keepalived.conf

主从节点都必须有的检测haproxy服务状态的文件(注:该文件必须有可执行权限!!!):
vim/opt/check_haproxy.sh
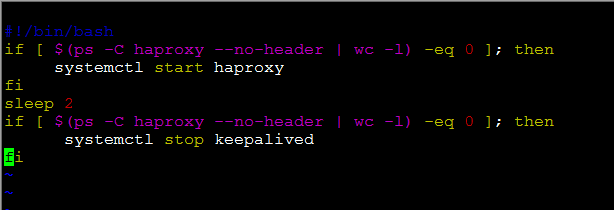
解释脚本:
#!/bin/bash
if[$(ps-Chaproxy--no-header|wc-l)-eq0];then###判断haproxy是否已经启动
systemctlstarthaproxy###如果没有启动,则启动haproxy程序
fi
sleep2###睡眠两秒钟,等待haproxy完全启动
if[$(ps-Chaproxy--no-header|wc-l)-eq0];then###判断haproxy是否已经启动
systemctlstopkeepalived###如果haproxy没有启动起来,则将keepalived停掉,则VIP
自动漂移到另外一台haproxy机器,实现了对haproxy的高可用
fi
注:有上述脚本可以看出,每次启动keepalived的同时,第一件事,就是先启动haproxy。
接下来测试VIP漂移:
此时为初始状态即keepalived和haproxy服务都没有启动。
首先 在主从节点分别查看eth0网卡情况:
主节点172.31.2.31:

从节点172.31.2.32:
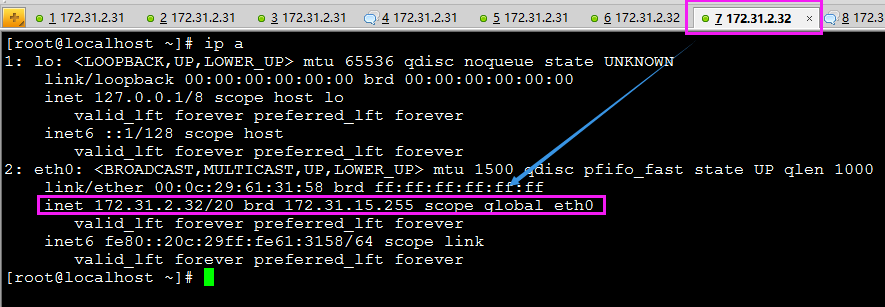
在从节点172.31.2.32上启动keepalived,在查看eth0网卡 (在启动keepalived的同时,首先会将haproxy启动)

这样我们可以通过请求172.31.2.100来达到直接访问172.31.2.32的目的(因为172.31.2.100是VIP,请求VIP则会自动将之转发到172.31.2.32):

上述在从节点启动keepalived完成。(VIP安装预期绑定到了eth0网卡)。
那么接下来实现将主节点172.31.2.31上的keepalived启动起来:
预测:由于172.31.2.31上配置的主节点的优先级比从节点高,因此,启动主节点的keepalived,则从节点上面172.31.2.100的VIP应该自动删除,漂移到主节点:
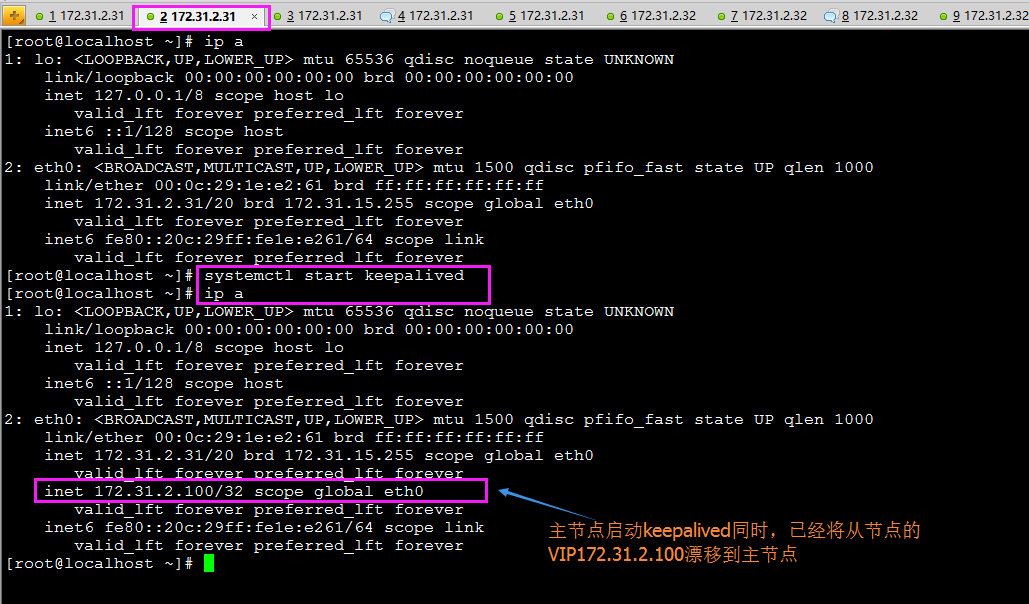
正常推测此时从节点的VIP应该不在了:

相关文章推荐
虚拟主机的专业参数,分别都是什么意思?2022-09-09
中非域名注册规则是怎样的?注册域名有什么用处? 2022-01-10
HostEase新年活动促销 美国/香港主机全场低至五折2021-12-28
HostGator下载完整备份教程分享2021-12-28
Flink中有界数据与无界数据的示例分析2021-12-28