资源管理框架(mesos/YARN/coraca/Torca/Omega)选型分析
- 来源:开源中国
- 更新日期:2018-03-28
摘要:资源管理框架(mesos/YARN/coraca/Torca/Omega)选型分析 博客分类: 架构 1 资源调度的目标和价值 1.1 子系统高效调度 任务之间资源隔离,减少争抢。 任务分配调度时结合资源分配,各个任务分配合理的资源,充分利用系统资源,减少资源利用不充分的问题。 资源调度结合优先级,优先级高的分配更多的资源。 1.2 提高全系统的资源利用率
1 资源调度的目标和价值
1.1 子系统高效调度
任务之间资源隔离,减少争抢。 任务分配调度时结合资源分配,各个任务分配合理的资源,充分利用系统资源,减少资源利用不充分的问题。 资源调度结合优先级,优先级高的分配更多的资源。

1.2 提高全系统的资源利用率
各个子系统,存在不同时期,对资源需求不一样的情况,平滑系统资源的利用。
1.3 支持动态调整切分资源,增强系统扩展性。
系统对资源的规划很难一次性准确,通过mesos支持虚拟主机的方式,动态扩展。
2 资源调度使用限制以及难点
2.1 资源调度使用限制
资源调度是为了提高资源利用率,分配本身是存在一定的开销的,对实时性要求非常高的应用不适合(毫秒,秒级别的应用)。
2.2 应用(框架)比较难规划资源
资源框架通过算法分配资源,但是每个细粒度的具体的任务对资源的需求非常难预估。规划如果偏差比较大,反而会降低系统本身的性能。
2.3 mem使用分配难题
JVM虚拟机存在内存回收的问题,这个不是程序本身是不能干涉的。内存很难分配准确,如果内存分配过少会导致任务失败。分配过多,造成资源浪费。
3 业界资源调度框架
3.1 Mesos
3.1.1 背景
Mesos诞生于UC Berkeley的一个研究项目,现已成为Apache Incubator中的项目,当前有一些公司使用Mesos管理集群资源,比如Twitter。
3.1.2 架构
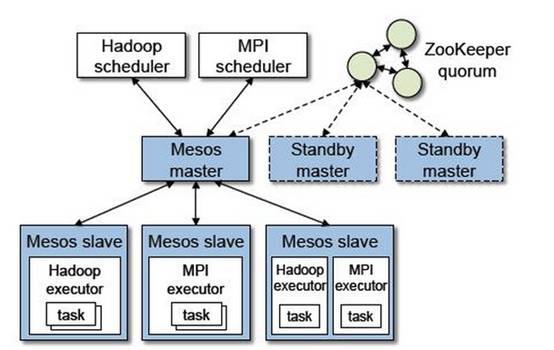
总体上看,Mesos是一个master/slave结构,其中,master是非常轻量级的,仅保存了framework(各种计算框架称为framework)和mesos slave的一些状态,而这些状态很容易通过framework和slave重新注册而重构,因而很容易使用了zookeeper解决mesos master的单点故障问题。
Mesos master实际上是一个全局资源调度器,采用某种策略将某个slave上的空闲资源分配给某一个framework,各种framework通过自己的调度器向Mesos master注册,以接入到Mesos中;而Mesos slave主要功能是汇报任务的状态和启动各个framework的executor(比如Hadoop的excutor就是TaskTracker)。
整个mesos系统采用了双层调度框架:第一层,由mesos将资源分配给框架;第二层,框架自己的调度器将资源分配给自己内部的任务。
在Mesos中,各种计算框架是完全融入Mesos中的,也就是说,如果你想在Mesos中添加一个新的计算框架,首先需要在Mesos中部署一套该框架; Mesos采用linux container对内存和cpu进行隔离。
3.1.3 优点
可以同时支持短类型任务以及长类型服务,比如webservice以及SQL service。 资源分配粒度粗,比较适合我们产品多种计算框架并存的现状。
3.1.4 缺点
Mesos中的DRF调度算法过分的追求公平,没有考虑到实际的应用需求。在实际生产线上,往往需要类似于Hadoop中Capacity Scheduler的调度机制,将所有资源分成若干个queue,每个queue分配一定量的资源,每个user有一定的资源使用上限;更使用的调度策略是应该支持每个queue可单独定制自己的调度器策略,如:FIFO,Priority等。
由于Mesos采用了双层调度机制,在实际调度时,将面临设计决策问题:第一层和第二层调度器分别实现哪几个调度机制,即:将大部分调度机制放到第一层调度器,还是第一层调度器仅支持简单的资源分配(分配比例由管理员指定)?
Mesos采用了Resource Offer机制(不同于Hadoop中的基于slot的调度机制),这种调度机制面临着资源碎片问题,即:每个节点上的资源不可能全部被分配完,剩下的一点可能不足以让任何任务运行,这样,便产生了类似于操作系统中的内存碎片问题。
3.2 YARN(Coroca)
3.2.1 背景
从hadoop 1.0发展而来,解决了hadoop1.0的单管理节点两个主要问题:
1、 单管理节点性能瓶颈。一个管理节点能管理的服务器不能无上限。
2、 Hadoop 1.0按照slot来划分资源,map slot的资源不能共享给reduce slot。造成资源浪费 很多公司都切换到hadoop 2.0,如淘宝天梯已经淘汰1.0,上线2.0。
3.2.2 架构
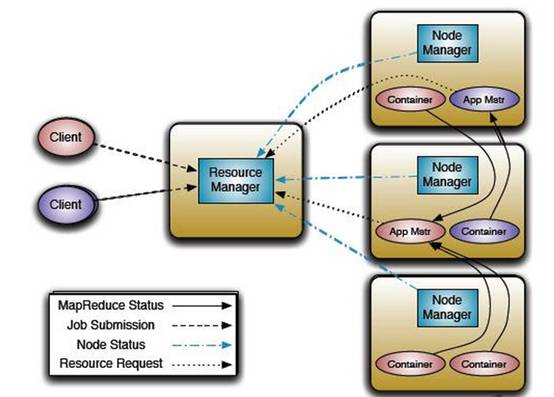
MRv2最基本的设计思想是将JobTracker的两个主要功能,即资源管理和作业调度/监控分成两个独立的进程。在该解决方案中包含两个组件:全局的ResourceManager(RM)和与每个应用相关的ApplicationMaster(AM)。这里的“应用”指一个单独的MapReduce作业或者DAG作业。RM和与NodeManager(NM,每个节点一个)共同组成整个数据计算框架。RM是系统中将资源分配给各个应用的最终决策者。AM实际上是一个具体的框架库,它的任务是【与RM协商获取应用所需资源】和【与NM合作,以完成执行和监控task的任务】。
调度器根据容量,队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用。这里的调度器是一个“纯调度器”,因为它不再负责监控或者跟踪应用的执行状态等,此外,他也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务。调度器仅根据各个应用的资源需求进行调度,这是通过抽象概念“资源容器”完成的,资源容器(Resource Container)将内存,CPU,磁盘,网络等资源封装在一起,从而限定每个任务使用的资源量。
调度器是可插拔的组件,主要负责将集群中得资源分配给多个队列和应用。YARN自带了多个资源调度器,如Capacity Scheduler和Fair Scheduler等。
ASM主要负责接收作业,协商获取第一个容器用于执行AM和提供重启失败AM container的服务。
NM是每个节点上的框架代理,主要负责启动应用所需的容器,监控资源(内存,CPU,磁盘,网络等)的使用情况并将之汇报给调度器。
AM主要负责同调度器协商以获取合适的容器,并跟踪这些容器的状态和监控其进度。
3.2.3 优点
YARN作为hadoop 2.0,hadoop各个组件都快速的接入YARN框架,未来发展很快,默认支持调度算法更丰富。
3.2.4 缺点
ResourceManager负责所有应用的任务调度,各个应用作为YARN的一个client library。传统数据库应用,接入之后效率不高,比较困难。
3.2.5 Coraca
Hadoop Corona是facebook开源的下一代MapReduce框架。其基本设计动机和Apache的YARN一致
(1) Cluster Manager 类似于YARN中的Resource Manager,负责资源分配和调度。Cluster Manager掌握着各个节点的资源使用情况,并将资源分配给各个作业(默认调度器为Fair Scheduler)。同YARN中的Resource Manager一样,Resource Manager是一个高度抽象的资源统一分配与调度框架,它不仅可以为MapReduce,也可以为其他计算框架分配资源。
(2) Corona Job Tracker 类似于YARN中的Application Master,用于作业的监控和容错,它可以运行在两个模式下:
1) 作为JobClient,用于提交作业和方便用户跟踪作业运行状态
2) 作为一个Task运行在某个TaskTracker上。与MRv1中的Job Tracker不同,每个Corona Job Tracker只负责监控一个作业。
(3) Corona Task Tracker 类似于YARN中的Node Manager,它的实现重用了MRv1中Task Tracker的很多代码,它通过心跳将节点资源使用情况汇报给Cluster Manager,同时会与Corona Job Tracker通信,以获取新任务和汇报任务运行状态。
(4) Proxy Job Tracker 用于离线展示一个作业的历史运行信息,包括Counter、metrics、各个任务运行信息等。 相比YARN,Coraca和hadoop耦合比较深,还是slot管理资源方式。基本参考YARN框架即可。
3.3 Torca
3.3.1 背景
Torca作为Typhoon云平台的关键系统也就应运而生,已经在网页搜索、广告等广泛应用。
3.3.2 架构
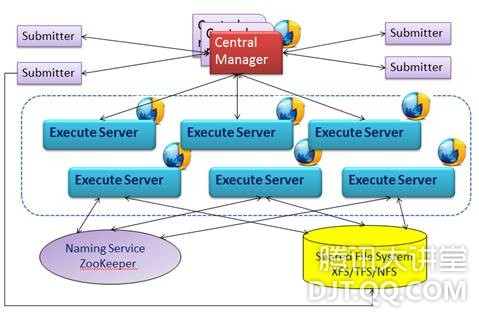
分central manager和execute server。central manager是集群的任务调度中心,包含以下模块
Master Daemon:负责启动/重启其他进程。
Scheduler:管理多个优先级的任务队列,根据任务描述文件生成任务ClassAd(分类广告),通过collector匹配任务与资源,下发任务至Execute Server。
Collector:集群的数据中心,负责从Execute Server收集机器及任务状态。机器的动态信息由Execute Server上报,一些静态信息及机器无法上报的信息如机位从CMDB拉取;同时,也是集群的匹配中心,对任务与资源的ClassAd进行匹配(MatchMaking)。
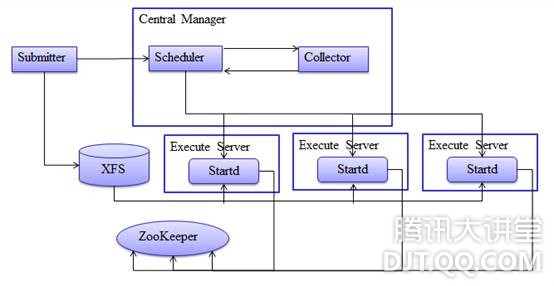
用户通过submitter和jdf提交job,如果作业依赖的文件在提交机本地,则submitter自动将其copy到xfs,并且用digest做标记,同时对job的各个属性进行解析,以及进行有效性检查,如果没有问题后,将生成最终的作业描述,发给CM上的scheduler。scheduler执行一定的调度策略,当决定这个job可以调度时,就将其发给collector,则collector会返回给scheduler满足条件的机器列表,scheduler就可以向这些机器发出启动task的流程了。Execute server根据job描述,准备相应的作业执行环境,分配资源,创建container等,就会启动task,并且在zk上记入该task相应的name信息。
3.3.3 优点
资源分配的有一个匹配的map的过程,而不是如mesos一样直接把所有资源先分给一个框架。分配算法更合理,可以参考。
3.3.4 缺点
模仿hadoop搞了一套私有的xfs,mapreduce,完全没有生态圈。
3.4 Omega
3.4.1 背景
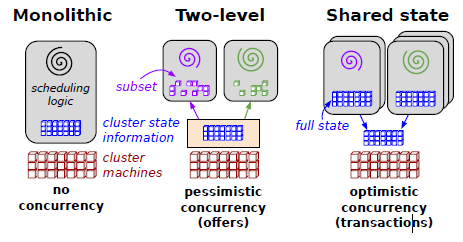
Google的论文《Omega flexible, scalable schedulers for large compute clusters》中把调度分为3代,第一代是独立的集群,第二代是两层调度(mesos,YARN)第三带是共享状态调度。
3.4.2 架构
为了克服双层调度器的以上两个缺点,Google开发了下一代资源管理系统Omega,Omega是一种基于共享状态的调度器,该调度器将双层调度器中的集中式资源调度模块简化成了一些持久化的共享数据(状态)和针对这些数据的验证代码,而这里的“共享数据”实际上就是整个集群的实时资源使用信息。一旦引入共享数据后,共享数据的并发访问方式就成为该系统设计的核心,而Omega则采用了传统数据库中基于多版本的并发访问控制方式(也称为“乐观锁”, MVCC, Multi-Version Concurrency Control),这大大提升了Omega的并发性。 由于Omega不再有集中式的调度模块,因此,不能像Mesos或者YARN那样,在一个统一模块中完成以下功能:对整个集群中的所有资源分组,限制每类应用程序的资源使用量,限制每个用户的资源使用量等,这些全部由各个应用程序调度器自我管理和控制,根据论文所述,Omega只是将优先级这一限制放到了共享数据的验证代码中,即当同时由多个应用程序申请同一份资源时,优先级最高的那个应用程序将获得该资源,其他资源限制全部下放到各个子调度器。 引入多版本并发控制后,限制该机制性能的一个因素是资源访问冲突的次数,冲突次数越多,系统性能下降的越快,而google通过实际负载测试证明,这种方式的冲突次数是完全可以接受的。 Omega论文中谈到,Omega是从Google现有系统上演化而来的。既然这篇论文只介绍了Omega的调度器架构,我们可推测它的整体架构类似于Mesos,这样,如果你了解Mesos,那么可知道,我们可以通过仅修改Mesos的Master将之改造成一个Omega。
3.4.3 优点
共享资源状态,支持更大的集群和更高的并发。
3.4.4 缺点
只有论文,无具体实现,在小集群下,没有优势。
4 Linux container介绍
LXC为Linux Container的简写。Linux Container容器是一种内核虚拟化技术,可以提供轻量级的虚拟化,以便隔离进程和资源,而且不需要提供指令解释机制以及全虚拟化的其他复杂性。相当于C++中的NameSpace。容器有效地将由单个操作系统管理的资源划分到孤立的组中,以更好地在孤立的组之间平衡有冲突的资源使用需求。与传统虚拟化技术相比,它的优势在于:
(1)与宿主机使用同一个内核,性能损耗小;
(2)不需要指令级模拟;
(3)不需要即时(Just-in-time)编译;
(4)容器可以在CPU核心的本地运行指令,不需要任何专门的解释机制;
(5)避免了准虚拟化和系统调用替换中的复杂性;
(6)轻量级隔离,在隔离的同时还提供共享机制,以实现容器与宿主机的资源共享。
总结:Linux Container是一种轻量级的虚拟化的手段。 Linux Container提供了在单一可控主机节点上支持多个相互隔离的server container同时执行的机制。Linux Container有点像chroot,提供了一个拥有自己进程和网络空间的虚拟环境,但又有别于虚拟机,因为lxc是一种操作系统层次上的资源的虚拟化。
5 选型建议
1)如果整个系统是hadoop应用和传统数据库并存的系统,可以考虑选用mesos,mesos是二层资源管理框架,更多的资源分配的权利提供了framework。
2)如果整个系统是纯粹的hadoop应用,考虑到YARN框架的发展,以及对框架开发对各个hadoop应用的支持,建议考虑YARN。
不管mesos和YARN本身,框架设计都考虑了的扩展性,但是原生的框架可能并非适用完全适用实际场景的应用,所以基于原有框架扩展分配策略是非常重要的,大家可以一起探讨下框架本身的限制以及修改扩展思路?
http://blog.csdn.net/iloveyin/article/details/30060017
相关文章推荐
虚拟主机的专业参数,分别都是什么意思?2022-09-09
中非域名注册规则是怎样的?注册域名有什么用处? 2022-01-10
HostEase新年活动促销 美国/香港主机全场低至五折2021-12-28
HostGator下载完整备份教程分享2021-12-28
Flink中有界数据与无界数据的示例分析2021-12-28